
Self-Supervised Contrastive Learning Fundamentals
Contrastive methods currently achieve state-of-the-art performance in self-supervised learning. It not only enables learning from unlabeled data but even pushes accuracies for supervised learning and search-retrieval tasks. AI giants like Google, Meta, OpenAI are actively working and publishing new methods in the fields to improve Self-supervised learning. It also happens to be my recent work and research interest. I will introduce some fundamentals of contrastive learning here to build understanding. In the next post, we will cover the progress we have made.
We will cover:
- Representation learning methods
- Ingredients of Contrastive Learning
- Applications
- Implementations - ML Libraries and Resources
Representation learning methods
There are three prominent self-supervised representation learning methods: generative, multi-task modelling, and contrastive. Generative representational learning approaches use autoencoder or adversarial learning to learn latent embedding space for regenerating images. As Generative methods typically operate directly in pixel space and require a high level of detail for image generation. This makes it computationally expensive, and bigger model size, which may not be necessary for representation learning.
Multi-task modelling is also a very powerful method for representation learning. It involves joint embedding space by performing multiple tasks such as classifications, detection, translation etc. It is being used in state-of-art big language models. However good task selection is very important. Otherwise, there may be suboptimal performance in unrelated tasks.
Contrastive methods currently achieve state-of-the-art performance in self-supervised learning. Contrastive approaches avoid a costly generation step in pixel space by bringing the representation of different views of the same image closer (‘positive pairs’) and spreading representations of views from different images (‘negative pairs’) apart.
Ingredients of Contrastive Learning
A few of fundamentals for contrastive learning are creating positive and negative pairs, using a proper distance measure to measure embedding distance, defining a good training objective which can optimise the distance, using a good model architecture to learn representations and then using good learning strategies for optimal flow of loss gradients for model learning. Let’s dive a little bit deeper into each aspect:
Positive and Negative Dataset
To perform contrastive learning, you need to positive and negative pairs. How they can be created depends upon whether the dataset is labelled or un-labelled. For labelled datasets, all images belonging to same class consist of positive pairs and from different classes as negative pairs. For unlabelled datasets, positive pairs are created via augmentation of same image and augmentation of different images constitutes negative pairs.
The amount of positive and negative samples is also very important. Siasemes Network used just a pair of images, positive and negative alternatively. Triplet Loss improved by using 3 images - anchor, positive and negative. Most of today’s state-of-art methods use multiple positive and negative samples. Larger the sample size, more information the model will have about the features it needs to bring closer or pull apart. For example, researchers from MoCo v3 presented that a negative sample size of 4000 is the optimal size for imagenet dataset.
If the negative sample size is smaller, hard negative mining can be used to find the most effective negative samples. It significantly speeds up the training. However negative hard mining is more effective in labelled data. In the case of unlabelled or noisy labelled data, hard negative mining results in the degradation of performance. Some recent work (BYOL, SwAV, VICReg, SimSiam) even showcase that just using positive samples yields better results, removing the need for negative samples altogether. However, these methods require longer training time.
Augmentation used in state-of-art methods for positive samples has converged to the combination of weak and strong augmentation from the SIMCLR method. One positive sample is generated through weak augmentation and another via strong augmentation. Then strongly modified image representation is used to bring closer to weakly modified representation.
Distance Measure
How the distance of two representation vectors is measured, directly affects the representation space learning. Some popular distance measures which can be used are Euclidian distance, cosine similarity, manhattan distance, KL divergence, JS divergence, Wassertain (EM) distance. Each of them imparts special properties to representational space. So choosing an appropriate distance measure is important.
Training objective
It calculates the final loss value using the distance of provided positive and negative sample. This loss value is used to optimise the model. Some of the popular loss functions are -
- Contrastive loss (Siamese loss)
- Triplet loss
- N-pair loss
- Lifted Structured Loss
- NCE and InfoNCE Loss
- Circle Loss
- Soft Nearest Neighbor Loss
- VICReg Loss
- SigLIP and SigLIT
Network Architecture
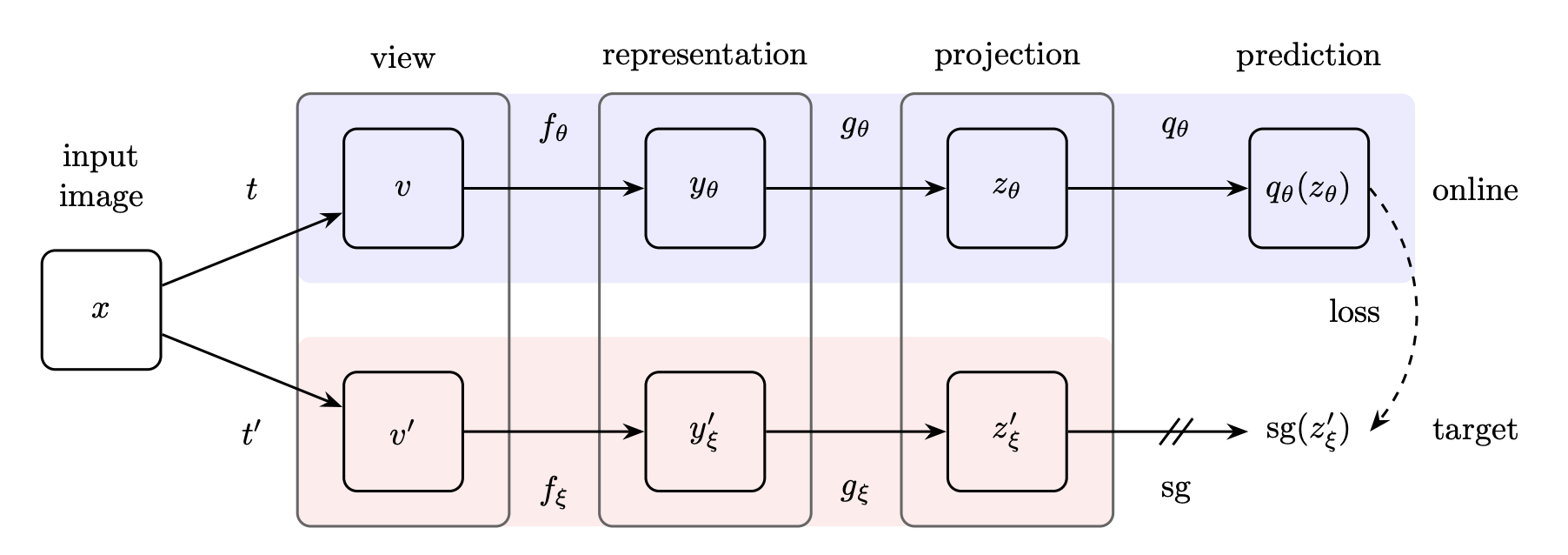
State-of-art methods use four-layer network architecture for contrastive learning - backbone model (view), representation layer, projection layer and prediction layer. Representation layer provides higher dimensional representation space, which can be used as input to the classifier or other downstream tasks. Projection layer is a lower dimension representation space which can be used for similarity measures. Prediction layer not only prevents collapse by providing asymmetry but also encourages the network to find features which are consistent between layers. Some approaches drop the prediction layer.
Learning Strategies
Grads Flow
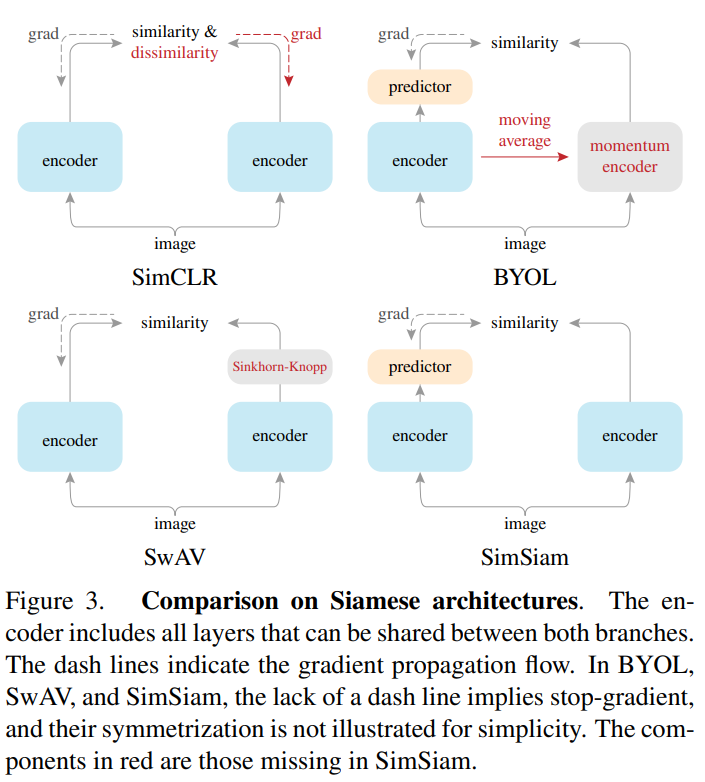
EMA
MoCo and BYOL models use EMA or momentum for target weight updates. It brings stability to representational space.
Target Temperature
In the case of a teacher-follower arm setup, teacher projection can be sharpened or the follower can be smoothened. It improves the feature sharpness of student.
Applications
Again, first, we should cover where it should not be used. It should not be the first step towards model/representation building. The use of pre-trained models via transfer learning is always a good start. There are some applications where it shines:
Label efficient training (one-shot/few-shot) - Self-supervised learning lets the model harness the power of unlabelled data to learn representation space. Linear evaluation or KNN-based methods in one or few shot provides significant results. It can further be used either finetuning with small labelled dataset or as a backbone for multiple classifiers on top. I can think of typical factory or medical oriented usecases where there is less labelled data or pre-trained model access and you need to work on multiple usecases. Here collecting large raw dataset is easy but building a well-labelled dataset not only requires experts for labelling but also is a challenging task.
Pretraining - Self-supervised achieves better results than transfer learning on pre-trained models even in fully labelled dataset availability.

Search and retrieval - Projector layer provides a really good feature vector to be used for search and retrieval of similar item search.
Implementations - ML Libraries and Resources
If you are in the TensorFlow ecosystem then TensorFlow Similarity is a really good option. It provides self-supervised learning on both labelled and unlabelled data, lets you control representation, projector and predictor layer configurations and have most state-of-art loss function implementations such as TripletMarginLoss, SoftNearestNeighborLoss etc.
Pytorch Metric Learning is a good library in the PyTorch ecosystem for labelled and unlabelled datasets. It also provides state-of-the-art loss functions, distance measures and miners for hard negative mining.
If you are a researcher, you can also look into official repositories. These are also well organised. I prefer this method more if I want to tweak and try out some new ideas.
Thank you for reading. There are some good references for further knowledge grasp:
- Review Blog — MoCo v3: An Empirical Study of Training Self-Supervised Vision Transformers
- Good Knowledge Blog - Contrastive Representation Learning, Lilian Weng
- Practical Insights Paper - Rethinking Self-Supervised Learning: Small is Beautiful


