Building a Transformer LLM with Code: Introduction to the Journey of Intelligence
The advent of "Attention Is All You Need" by Vaswani et al. in 2017 marked a monumental milestone in the development of Language Models (LLMs). It revolutionized language processing with its Transformer Architecture based on a novel MultiHead Attention Mechanism (Q, K, V). It further provided a practical bidirectional encoder, the iterative decoder and the causal decoder architectures to efficiently solve NLP use cases. Andrej Karpathy's Let's build GPT: from scratch video fundamentally showcased the power of the same transformer in recent large language models. This video inspired me to consolidate further developments in transformer architectures in recent LLMs via code. Let's embark on a journey into the world of modern LLMs with a conceptual introduction and explore their transformative capabilities.
We will cover:
- The Transformer: A Fundamental Building Block
- Evolution of Transformers
- Pretraining: Unlocking Language Knowledge
- Emergence and Applications
- Alignment: Ensuring Ethical and Human-Aligned Behavior
- Finetuning: Domain-Specific Adaptation
The Transformer: A Fundamental Building Block
At the core of modern LLMs lies the Transformer architecture. The attention paper introduced the following key components:
- Efficient Attention Mechanism: Introduced Q, K, V attention mechanism enabling parallelization and scalability, with techniques like scaling and softmax for optimal attention distribution. MultiHead attention enhanced model performance.
- Transformer Architecture: Good model architecture with position encoding, Multi-Head attention, layer norm, MLP-based non-linearity, and residual connections. Efficient for optimizing large models.
- Encoder Architecture: Efficient bidirectional transformer architecture to consume and encode information into embedding space.
- Decoder Architecture: Iterative decoding architecture generates natural text step by step. It can also utilize encoded encodings for guidance, enhancing capability and quality.
- Causal Decoder: Efficient unidirectional decoder packing multiple sentence variations into a single batch, improving training efficiency.

The attention mechanism calculates the output as a weighted sum of the values, where the weight assigned to each value is determined by the scaled dot-product of the query with all the keys:

Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. Finally, Multi-Head attention is integrated with layer norm, MLP-based non-linearity, and residual connections to form the transformer block. The transformer-based versatile Encoder-Decoder model enables LLMs to excel in various language tasks such as machine translation and text generation, thanks to its ability to capture contextual dependencies and generate coherent output. Overall, these components provided three fundamental advantages to transformers to revolutionise the AI roadmap:
- Expressiveness: A generic architecture allows it to capture intricate language patterns and semantics. It can capture global context, learn long-term dependencies in sequences and can also scale across modalities.
- Parallelization: Transformers can process input sequences in parallel, unlike sequential models like RNNs. It enables faster training and inference of larger models on large datasets and larger input contexts.
- Optimization: Finally, the transformer architecture with layer norm and residual connections provides the ability to train deep models capable of showcasing emergent behaviours.
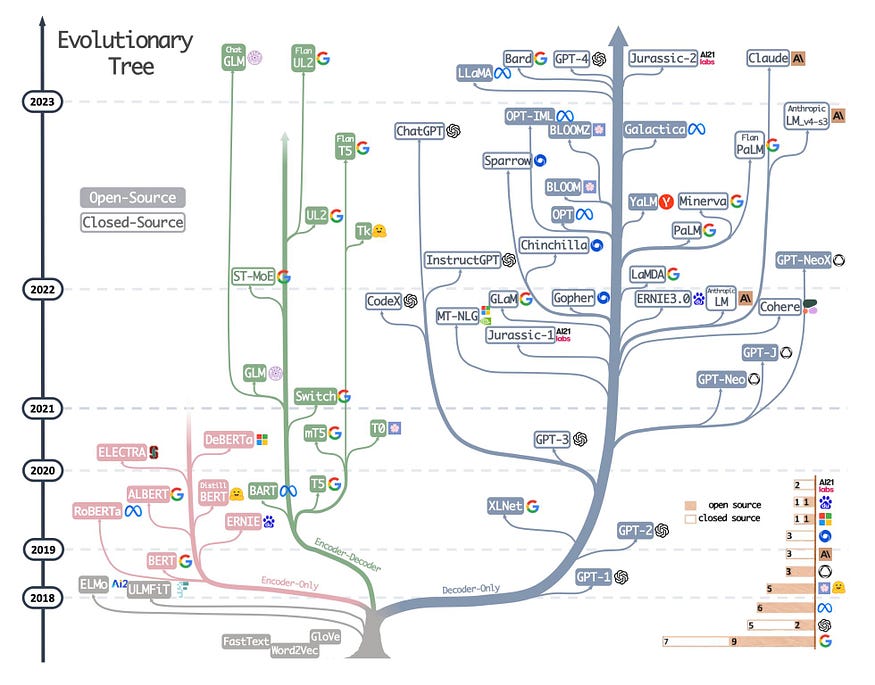
Evolution of Transformers
The first evolution of LLMs happened in model architecture from Encoder-Decoder to Encoder-only, Decoder-only, and prefix decoders.
- Encoder-Decoder: Traditional encoder-decoder architecture. BART, T5, FlanT5.
- Encoder-only: Consists of only the Encoder part of the Transformer architecture. Adept at capturing contextual representations of input sequences and have been extensively used in various embedding models. BERT, MiniLM etc.
- Decoder-only: Most successful architecture in scaling language generation tasks. iteratively next-word generation makes the task easier and causal decoder makes training efficient. GPT-series, OPT, llama, BLOOM etc.
- Prefix Decoders: It utilizes a bidirectional attention mechanism to encode the prefix and decodes the rest of the output tokens autoregressively using causal attention. PaLM.
A causal decoder has the advantage of spreading the computational and cognitive load by generating one word at a time. For example, for generating a text containing 100 words (tokens), the model will perform 100 passes and will be able to utilise 100x computing with the same parameters. This simplifies the task and improves the performance. Similar examples of improving capabilities by spreading cognitive and computing load are also manifested in other domains. In Image generation, the diffusion models also leverage similar strategies to outperform GAN models. However, similar to GigaGAN, scaling of the model and training of encoder models can also lead to an equally capable and more efficient inference. With further improvement in computing, more architectures similar to prefix decoders will emerge.
Another evolution happened within the transformer block to improve the capabilities and efficiency. Some of the notable ones are:
- Integrated Positional embeddings - Fixed, Relative PE (T5), RoPe (llama), AliBi (MPT)
- Attention optimisations - Efficient attention mechanisms such as Sparse Attention(BIG BIRD), FAVOR+ (Performer), MultiQuery Attention (Falcon), and Sliding Attention (Longformer).
- Feedforward Network - Optimisations use of CNNs, routing mechanisms
A Survey of Large Language Models paper succinctly summaries the significant LLM model architecture in a table:

Pretraining: Unlocking Language Knowledge
The pretraining phase is the initial step in the development of modern LLMs, where the model learns from a massive amount of text data without specific task supervision. Training objectives involve either predicting the next word/token(causal decoders) or predicting missing words in a given context. The other objective is also known as "masked language modelling," where a certain percentage of tokens in the input sequence are randomly masked, and the model is tasked with predicting those masked tokens based on the context. This unsupervised learning process allows the model to gain a deeper understanding of language and form a strong word representation which led to the emergence of intelligence.
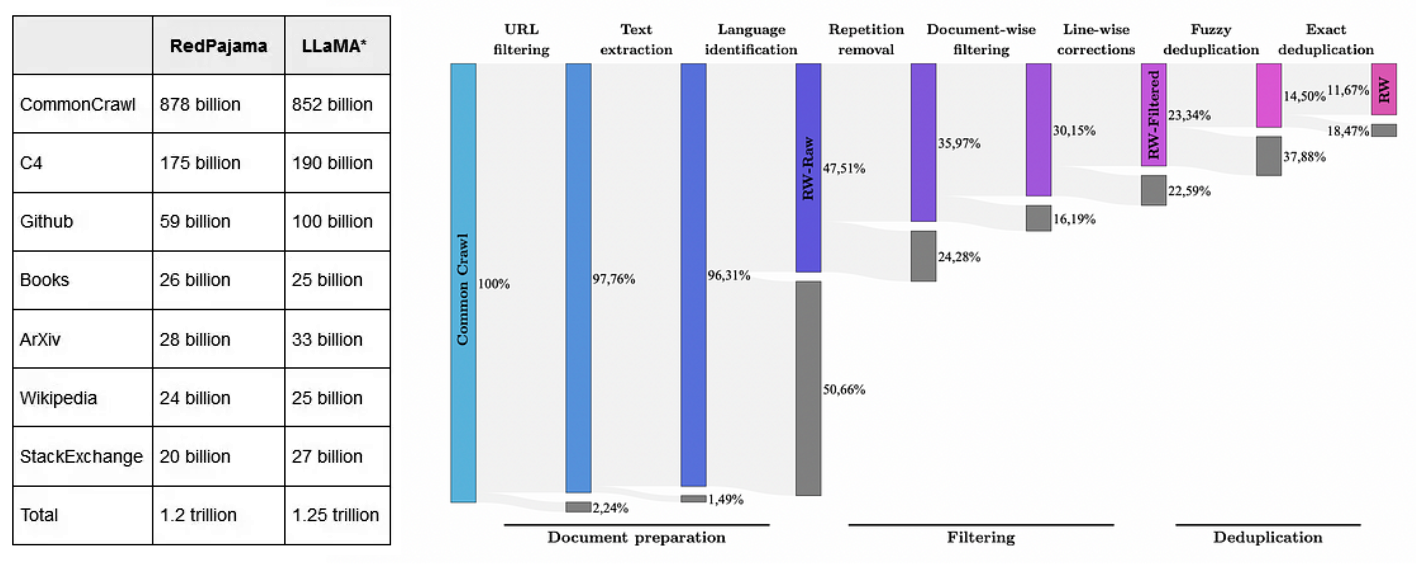
The size and quality of the training dataset are very essential for generating good-quality LLM. Scaling laws provides a relationship between optimal dataset requirements for a large model for optimal training [calc]. Smaller models can still be trained on bigger datasets but with diminishing returns. In today’s LLMs, the pretraining is performed on a trillion token scale dataset aggregated from the web, books, wiki, GitHub and other sources. Llama and RedPajama were pre-trained on 1.2T tokens. Falcon improved the performance over Llama and RedPajama by refining the collected dataset through multiple stages of filtering. Llama 2 further improves the base performance by training on 2 trillion tokens. The fineweb-Edu dataset further improved training efficiency.
While training objectives are usually simple, the dataset and model size requires a different scale of infrastructure to support large-scale pretraining. It usually incorporates 250-2048 GPUs and costs around 1-10M USD to train 10 billion parameter scale models. Bloom's blog is a good read on what goes behind a large-scale pretraining infrastructure. Also, simons blog provides good estimates.
Emergence and Applications
Emergent properties in language models highlight an intriguing phenomenon: as the number of parameters increases, performance initially fluctuates randomly until reaching a critical threshold. At this point, a distinct property emerges, leading to a remarkable improvement in performance. Despite a lack of complete understanding of this phenomenon, the "World model" hypothesis suggests that predicting the next word effectively requires learning to model the world. As the number of parameters increase, these models develop more comprehensive representations of human knowledge and language, essentially forming these mini “world models”. This critical juncture empowers the models with a heightened understanding of human language and enables contextually nuanced responses. As a result, they become valuable assets across various applications, including language translation, text generation, and interactive virtual assistants.
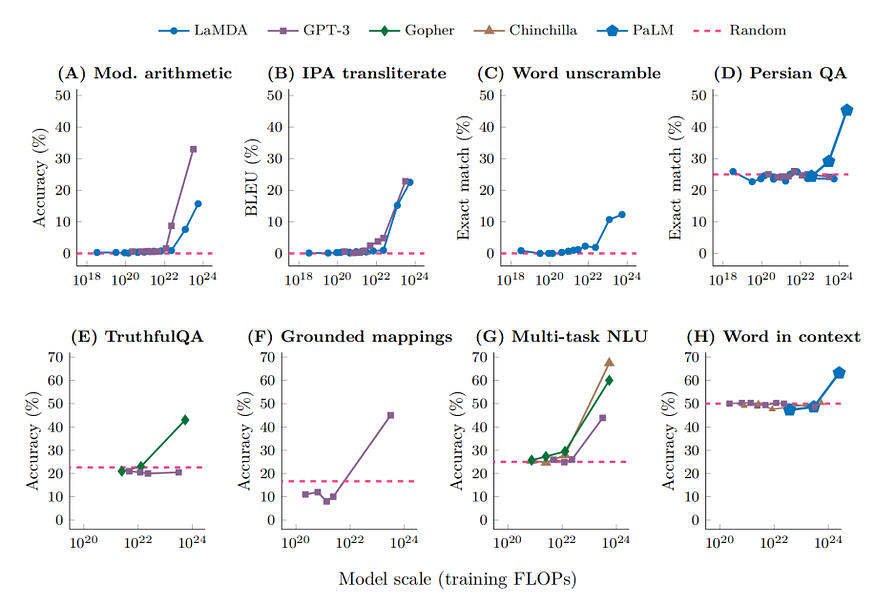
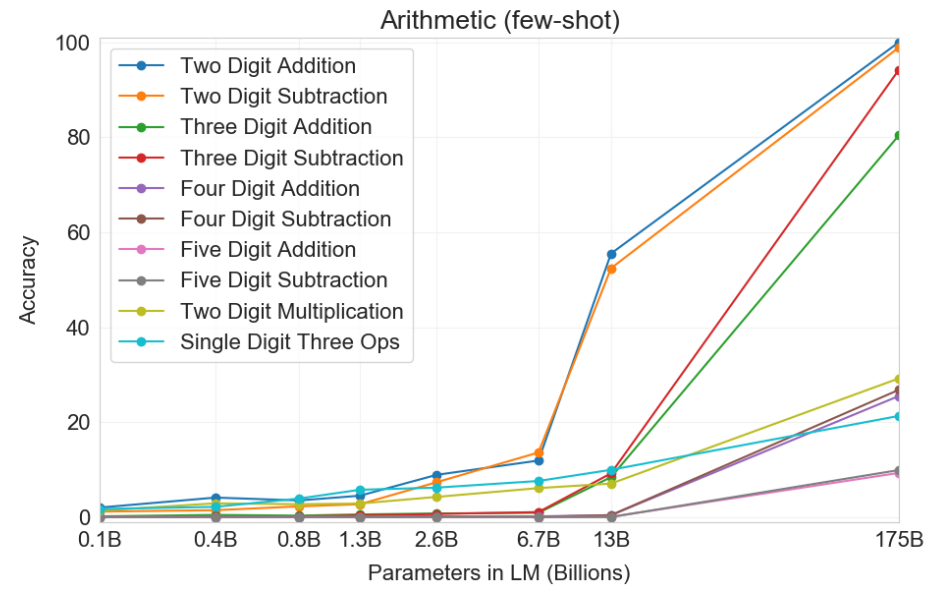
Emergent abilities of large language models. Image Source
Alignment: Ensuring Ethical and Human-Aligned Behavior
Pretrained LLMs may exhibit intelligent behaviour, but their training to predict the next word on vast internet text can also lead to generation outputs that are untruthful, toxic, or reflect harmful sentiments. In other words, these models' outputs aren’t aligned with their users' desired behaviour. Also, user-aligned behaviour is not enough. A user might ask to kill another human or a terrorist group might utilise the LLM intelligence for malicious purposes. This leads to the requirement of safety and ethics in AI. As we are rapidly progressing towards superintelligence, alignment becomes even more crucial.
To address human alignment, OpenAI introduced reinforcement learning from reinforcement learning from human feedback (RLHF) technique. Additionally, for a more robust embodiment of human ethics principles, Claude utilizes constitutional AI to make it safer and interpretable.

Finetuning: Domain-Specific Adaptation
Fine-tuning adapts pre-trained models to specific tasks or domains using smaller labelled datasets. During pretraining, LLMs gain a comprehensive understanding of language and accumulate a vast knowledge base. The transformer models transfer their general language knowledge to new tasks, demonstrate domain generalization capabilities, and deliver improved performance on downstream tasks, all with the utilization of only limited labelled data. This two-step approach empowers LLMs to excel in a wide range of practical applications, showcasing their adaptability and versatility.
Galactica uses a mixing of pretraining data with finetuning data to unlock alignment without harming base transformer capabilities. Orca's progressive learning is driven by careful sampling and selection of extensive and diverse imitation data. This data is further enriched by incorporating valuable signals from GPT-4, such as explanation traces, step-by-step thought processes, and complex instructions. LIMA by Meta also uses a 65B parameter LLaMa language model fine-tuned with the standard supervised loss on only 1,000 carefully curated prompts and responses, without any reinforcement learning or human preference modelling to provide a competitive model.
Due to the large scale of LLMs, Fine-tuning is also very costly. It leads to the emergence of Parameter-Efficient Fine-Tuning (PEFT) methods to enable efficient adaptation of pre-trained language models to various downstream applications by only fine-tuning a small number of (extra) model parameters. These are also often utilised to distil larger and more intelligent models into smaller models. However, The False Promise of Imitating Proprietary LLMs showcases that there exists a substantial capabilities gap between open LM using PEFT techniques and closed LMs. Vicuna like open LMs easily copy persona from chatGPT/GPT4 but they significantly lack base reasoning and factuality capabilities.
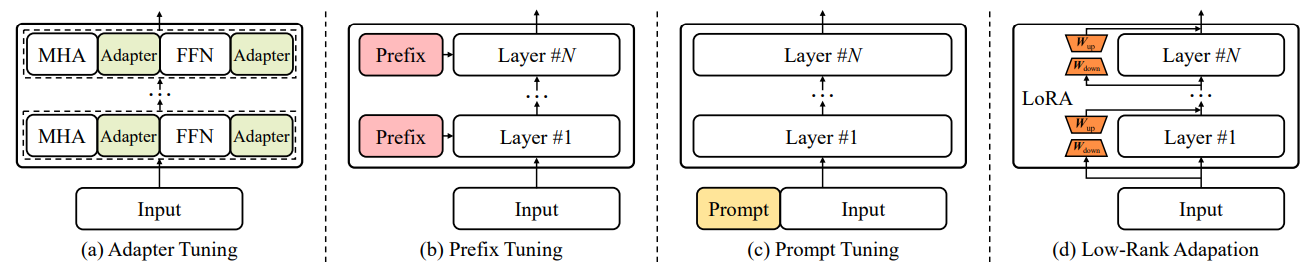
What's Next?
In our upcoming blog, we will embark on an exciting journey of coding a transformer model inspired by Karpathy's tutorial. Taking it a step further, we will implement optimizations such as weight tying, flash attention, and other enhancements to create an even more powerful and efficient model.


